You Got Me Dancing (undergrad project)
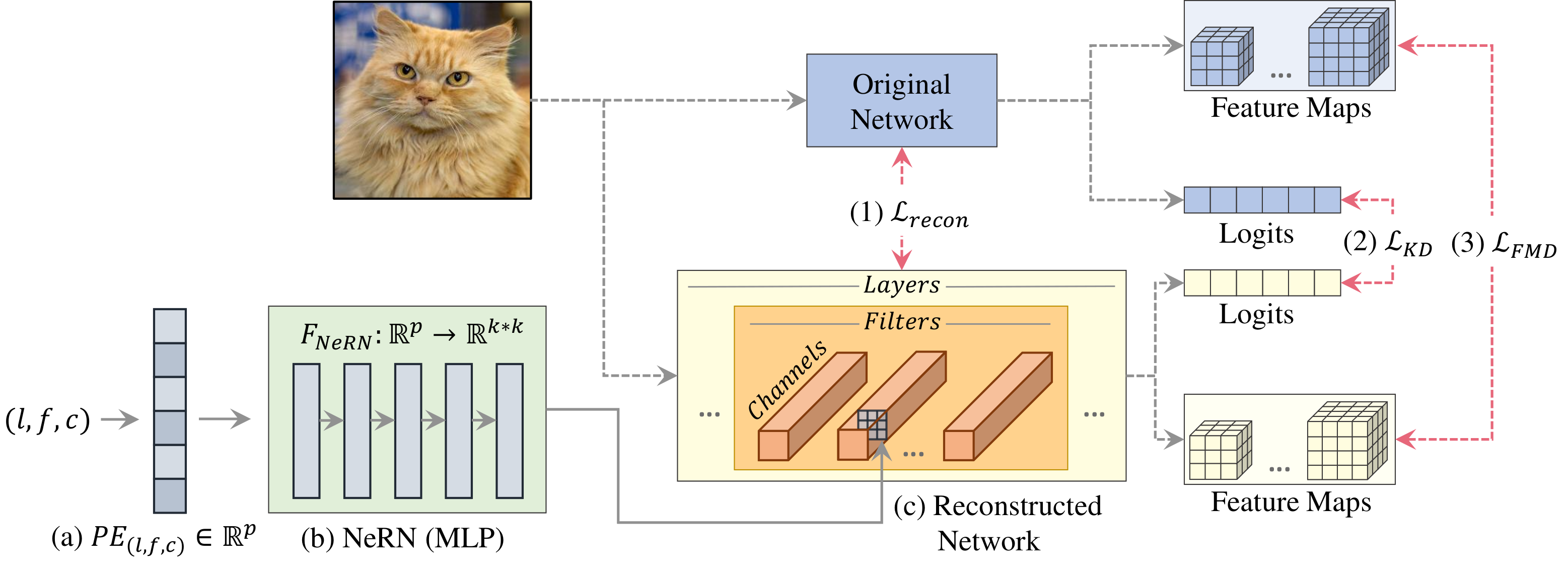
Motion Transfer, the task of re-enacting the image of a person according to the movement of another, is an active research field in computer vision. While recent methods achieve realistic looking results in controlled scenarios, it is challenging to obtain similar results in the case of complex, crowded, in-the-wild scenes. In this work we tackle this task, while integrating the synthesized person into the real-world target scene. We call this task Scene Aware Motion Transfer (SMT). In order to achieve a robust solution, we introduce a novel workflow that harnesses a set of models, each attaining state-of-the-art results in its respective field. We first construct a novel person tracking workflow to separate each unique identity from the people in the scene. Then we utilize the tracking results for a targeted single-person motion transfer, resulting in a fully automatic workflow that handles complex videos. Extensive evaluation is presented to show the quality and robustness of the results in different scenarios.